Efficiently harnessing generated data is a crucial endeavor for unlocking its full potential. Imagine the scenario of an insurance company, submerged in a sea of paperwork stored haphazardly across various units. Consider the challenge of retrieving critical cross-referenced information from scattered files. This predicament resonates with diverse businesses struggling to consolidate and extract value from their scattered data sources. Thus, it becomes paramount to devise strategies to address the challenges posed by data silos across platforms and channels, enabling accurate reporting and analytics. According to a study conducted by Deloitte, industry leaders found that there were three challenges in achieving data management goals by an organization. These are collecting, organizing and securing increasing data volumes, constant changes in the regulatory landscape and the cost and complexity associated with data protection.
Data Stitching
Data stitching involves integrating data from disparate sources across functions, empowering businesses to extract deeper insights and prompt targeted actions. This process grants resources access to granular data, ultimately enhancing overall business performance.

Data Warehousing and ETL
Data originates from various sources like databases, internal applications (e.g., ERP or CRM), flat files, physical device measurements, discarded web data, or internet-streaming applications. A data warehouse (DWH) is a repository that extracts and stores data from operational systems, making it accessible for queries and reporting. Organizing data in a meaningful manner within the DWH facilitates day-to-day operations, analysis, and reporting, enabling businesses to discern trends and devise strategic approaches. Extraction, Transformation and Loading (ETL) involves collecting data, validating and transforming it, and loading it into data lakes or warehouses. A well-structured ETL system enhances accuracy and streamlines data handling. Automated scripts are commonly employed in ETL processes. Since this process of ETL is complex and difficult to implement for all enterprise data, powerful players like AWS have come into play. Enter Amazon introduced AWS Glue.
Introducing AWS Glue
AWS Glue stands as a prominent serverless ETL tool, leveraging a code-based interface to expedite data integration for machine learning, application development, and analytics. Data integration encompasses several stages: data identification and generation from diverse sources, enrichment, normalization, and merging.
AWS Glue empowers data integration through the following three core components.
- AWS Glue Data Catalog serves as the central metadata repository, housing metadata tables that point to individual data stores. This index stores information about data schema, location, and runtime metrics, crucial for identifying ETL job targets and sources.
- The Job Scheduling System automates and interconnects ETL pipelines, offering a flexible scheduler capable of event-based triggers and job execution schedules.
- The ETL Engine is responsible for generating customizable ETL code in Python or Scala.
AWS Glue significantly reduces the time required to prepare data for analysis. It identifies and lists data, generates necessary Scala or Python code for data transmission from the source, and handles loading, and transformation based on planned events.
AWS Glue is an established, user-friendly ETL platform boasting intuitive features and robust support. Gemini Consulting & Services can help you leverage AWS Glue and accelerate the integration of enterprise data. Contact us to learn how AWS Glue can benefit your organization.
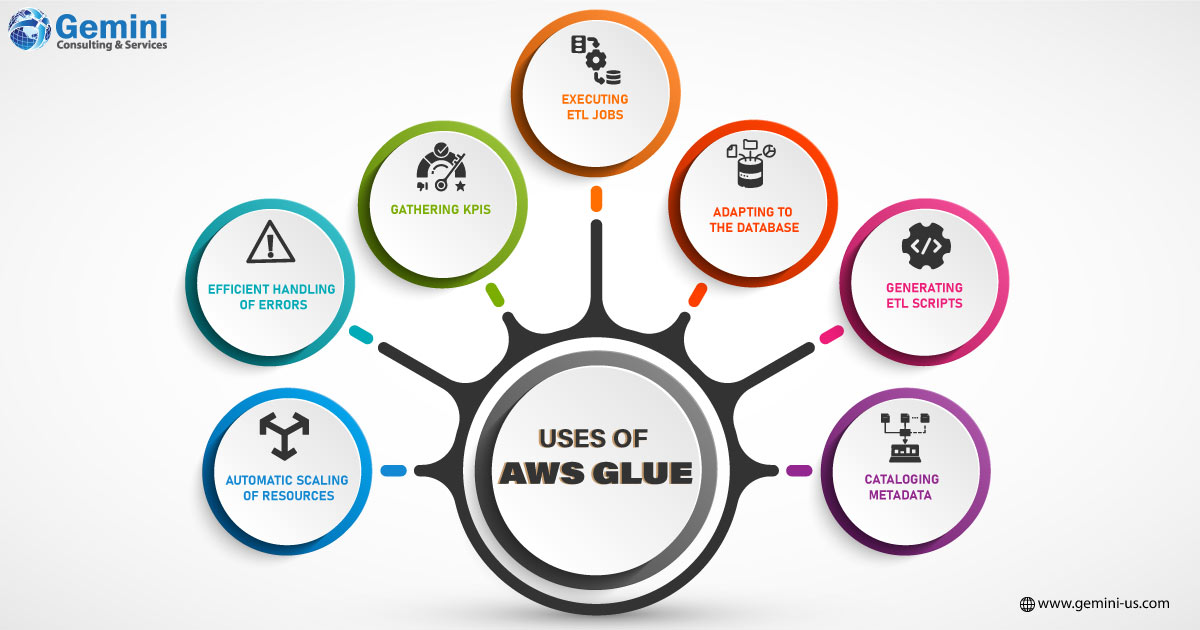
While catering to diverse user types, AWS Glue finds favor among organizations aiming to establish enterprise-class data warehouses. The platform seamlessly facilitates data movement from sources to the data warehouse, making it a preferred choice for such enterprises. Additionally, it supports loading data from both streaming and static sources.
This approach aims to consolidate critical data from various sources into a central data warehouse. This empowers business users to access, compute, and manage tasks including:
- Scaling resources automatically based on demand. Implementing error handling and retries without interruptions.
- Gathering KPIs, metrics, and ETL logs. Executing ETL jobs triggered by events, schedules, or triggers.
- Adapting to database schema changes.
- Generating ETL scripts for data enrichment, normalization, and transformation during transfer.
- Cataloging metadata of data stores and databases in AWS Glue Data Catalog.
Advantages of AWS Glue
- AWS Glue handles and executes all ETL tasks without requiring server provisioning, configuration, or lifecycle management.
- Crawlers with automated schema inference simplify data discovery for structured or semi-structured datasets.
- It acts as a metadata repository, enhancing data visibility and asset tracking.
- For users creating custom ETL scripts, “developer endpoints” streamline the development process.
- AWS Glue offers user-friendly tools for creating and managing job tasks based on schedules and triggers.
- Flexible pay-as-you-go pricing eliminates the need for long-term subscription commitments.

